
- dev
- ops
- football
- making lists
Categories
Archives
- April 2013 (1)
- November 2010 (1)
- March 2010 (1)
- December 2008 (1)
- October 2008 (1)
- September 2008 (1)
About
sayap is a code monkey who writes long ticket description and even longer commit message to bore future maintainer to death.
sayap lives in Malaysia, and follows timezone
EPL/Arsenal.

Garbage in, Xmltv out
December 31, 2008 at 04:48 AM | categories: boleh | View CommentsAs a follow up to my previous post, I am going to rant about my poor experience with screenscraping. Although the xmltv grabber, in its current incarnation, works with listings from The Star and Astro, the script was initially written to target the official websites for TV3/NTV7/8TV/TV9 (Media Prima) and RTM1/RTM2 (RTM).
To understand why the idea was ditched, here's a sample line of html from TV3 (reformatted for sanity):
<td> <a id="plcRoot_Layout_zoneCenter_ContentPlaceHolder_partPlaceholder_Layout_zoneScheduleContent_TV3ScheduleContent_ScheduleMain1_dlScheduleToday_ctl04_lnkShow" title="Date: Aug 19, 2008<br>Time: 10:00 AM - 10:02 AM" class="ScheduleLink" onmouseover="this.T_STICKY=false;this.T_WIDTH=300;this.T_FONTCOLOR='#000000';this.T_FONTFACE='Verdana';this.T_PADDING=5;this.T_BGCOLOR='#FFFFFF';this.T_TITLE='BERITA TERKINI';this.T_STATIC=true;return escape('Date: Aug 19, 2008<br>Time: 10:00 AM - 10:02 AM');" href="/Shows/MainNormal.aspx?MasterID=258&ShowID=322&MenuID=1&TemplateID=3" > BERITA TERKINI </a> </td>
It contains an id that is 150 characters long, multiple unescaped closing angle brackets, and some funky onmouseover code. Truely thedailywtf.com material. Oh ya, the html file with little content approaches 100K in size.
TRWTF about Media Prima websites, however, is the lack of consistency. All 4 sites appear to be running the same ASP.NET app, but subtly, each one is different:
-
It is
Schedules.aspxon TV3 and NTV7,ScheduleToday.aspxon 8TV, andSchedule.aspxon TV9. -
To get today schedules, you need to pass in query string parameter
view=todayto TV3, NTV7, and TV9. 8TV, of course, doesn't need it. -
NTV7 only contains partial listing and will truncate shows that have been aired from the list. TV9 contains partial listing but doesn't truncate. TV3 and 8TV contain full listing and doesn't truncate. IMHO, Media Prima should change one of them to contain full listing with truncation. Then we will have a permutation.
-
If you feel adventurous, you can probably get around the truncation by simulating ASP.NET's postback and using the lovely calendar widget that has number-of-days-since-2000-01-01 as its parameter. If you feel adventurous, and have too much time in your hands.
Bashing aside, one good thing about Media Prima is that they are not afraid to show you what's under the hood. I just checked the 8tv schedules and was presented with this error message, embedded in the page:
[Error loading the WebPart '8TVScheduleSubNavi'] C:\Inetpub\wwwroot\mediaprima\8tv\CMSWebParts\8TV\Schedule\8TVScheduleSubNavi.ascx(17): error BC30451: Name 'LinkHelperClass' is not declared.
Awesome.
In comparison, RTM website is surprisingly good.
-
Both RTM1 and RTM2 pages are consistent to each other. This is a small feat, but I have to mention it.
-
The date parameter follows ISO8601, i.e.
YYYY-MM-DD, unlike Media Prima websites that expect 3 parameters for day, month, and year. Kudos to the developers. -
The page size is 6 times smaller compared to Media Prima.
-
The listing follows the newspaper day (i.e. from morning until the next morning), rather than the actual day (i.e. from midnight to midnight). This is good usability.
-
It has reliability issue at times -- RTM1 listing is blank since 2008-12-28.
As for Astro website, there is nothing much to talk about. Overall, it is just OK.
-
Pages are consistent.
-
The date parameter uses the format of
DD-MON-YYYY. -
A day of schedules is splitted into 2 pages, one for AM, one for PM. This is cumbersome not only for the script to scrape, but also for an actual person to read.
-
Things like No Transmission and Transmission Ends are included as shows with start time and duration. This isn't really necessary.
-
The size of the page is 3 times bigger compared to RTM.
The Star website has its goods and bads, but still, it is the best among the bunch.
-
Pages are consistent.
-
The date parameter uses the format of
MM/DD/YYYY. Ugh. -
The listing contains columns for description and episode. This is a major plus. However, the episode column contains a mix of English words and Arabic numerals. It has to be more consistent.
-
The listing follows newspaper day (duh).
-
It spells SpongeBob SquarePants correctly. Shame on you, Astro.
Lastly, the web designers for RTM/Media Prima/Astro/The Star really need to start learning how to use CSS to properly separate content from presentation. Seriously. Let's just start by giving a freaking id (that is less than 150 characters) to the freaking schedules tables, so that I don't have to rely on some bizzare bgcolor attributes to identify them. Amen.
Mythtv's xmltv grabber for Malaysia channels
December 30, 2008 at 11:08 PM | categories: python, boleh, linux | View CommentsEver since I got mythtv up and running months ago, I have always wanted to use the Electronic Program Guide (EPG) feature. Unfortunately, getting tv schedules in a format understandable by mythtv (i.e. xmltv) is not so easy.
From a bit of googling, I found 2 (non-)solutions. The first one involves using tvxb through wine to grab tv schedules from Astro through screenscraping. Apparently, it doesn't work anymore, as the tvxb site is showing the following message:
All Astro satellite channels (No longer works - needs updating. 2008/10/12)
The other solution is a perl script written by Shahada Abubakar that also screenscrapes Astro listing. Like the first one, this solution has also ceased to be working, due to the flaky nature of screenscraping.
Of course, the googling and testing were just unnecessary foreplay. I was set at the beginning to come up with my own solution anyway. With the help of wonderful python libraries such as BeautifulSoup and lxml, I wrote a xmltv grabber that:
-
can screenscrape either Astro or The Star listings for channels rtm1, rtm2, tv3, ntv7, 8tv, and tv9
-
is functioning as of 2008-12-31 (UPDATE: broken as of 2013-01-27, ugh)
Here's the script: grabmy.py
To get it to work, install the requirements first:
easy_install BeautifulSoup lxml httplib2 python_dateutil
Then, run the script to generate a xmltv file:
python grabmy.py -f my.xml
Feed mythbackend with the file:
mythfilldatabase --file 1 my.xml
And finally, here's the EPG in its full glory if you channel-flip at 2am:
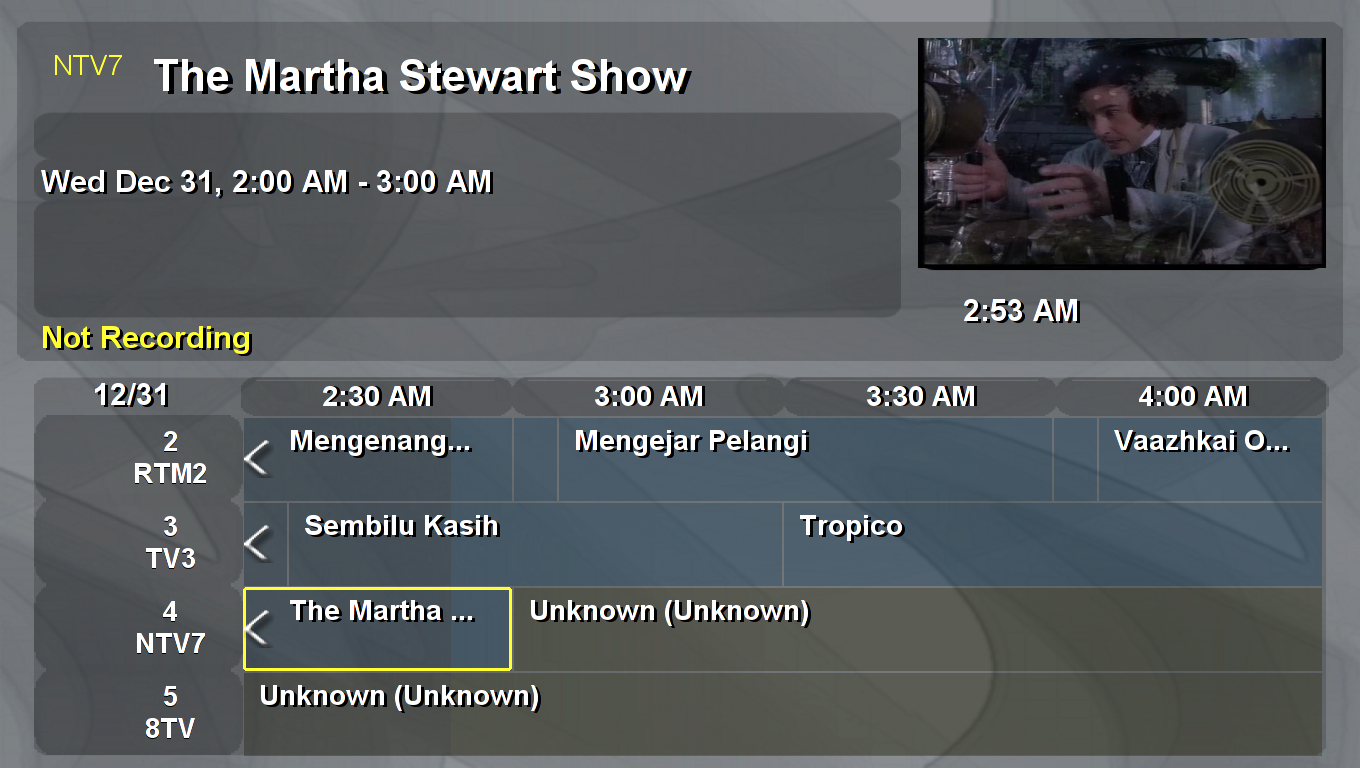
How to start a blog
September 19, 2008 at 09:59 PM | categories: meta, boleh | View CommentsHere's how a normal person starts a blog:
-
Make a coin toss. Heads for wordpress, tails for blogger, middle for others.
-
Sign up.
-
Blog like a normal person.
Of course, blogging like a normal person is pretty boring. For one, if you blog like a normal person, you won't even get arrested under ISA. Boring. * yawn *
So here's how a real man starts a blog:
-
Spend a few days looking for a server that is cheap, fast, and has a reasonably not-slow connection to whatever 3rd world country that you happens to live in.
-
Call your credit card company to authorize the payment for the server, all the while resisting the urge to explain that the transaction is not for porn.
-
Spend a few days looking for a blog software that doesn't have any freaking release yet, let alone a stable one. Spend a few nights setting it up -- in a 3rd world country, you get slightly less sucky connection in the off-peak hours.
-
Realize that unstable really does mean unstable, and the software is just unuseable. Nonsense. A magical touch of
hg revert -r 486 .makes it production ready, and you are good to go. -
Blog about how to start a blog (to mask the fact that you have totally forgotten what you wanted to blog about in the first place).